
1장. 데이터 분석 기획의 이해
1절. 분석기획 방향성 도출
분석기획의 특징
분석기획이란?
- 분석을 수행하기 전에 수행할 과제를 정의하고, 의도한 결과를 도출하기 위해 관리 방안을 사전에 계획하는 작업
데이터 사이언티스트의 역량
- 수학/통계학적 지식 및 정보기술, 해당 비즈니스에 대한 이해와 전문성을 포함한 3가지 영역에 대한 고른 역량과 시각이 요구
분석 대상과 방법
- 분석의 대상(What)과 분석의 방법(How)에 따라서 4가지로 나뉜다

출처: https://needjarvis.tistory.com/505
- 최적화(Optimization): 분석 대상 및 분석방법을 이해하고 현 문제를 최적화 형태로 수행
- 솔루션(Solution): 분석과제는 수행되고, 분석 방법을 모를 경우 솔루션을 찾아서 분석 수행
- 통찰(Insight): 분석 대상이 불분명하지만 분석 방법을 알 경우 인사이트 도출
- 탐색(Discovery): 분석 대상과 방법을 모를 경우 탐색을 통해 분석 대상 자체를 새롭게 도출 가능
목표 시점 별 분석 기획 방안
- 과제 중심적인 접근 방식: 당면한 과제를 빠르게 해결
장기적인 마스터 플랜 방식: 지속적인 분석 내재화
- 분석기획에는 문제해결을 위한 단기적인 접근 방법과 분석과제 정의를 위한 중장기적인 마스터 플랜 접근 방식을 융합하는것이 필요

출처: https://needjarvis.tistory.com/505
- 의미있는 분석을 위해서는 분석 기술, IT 및 프로그래밍, 분석 주제에 대한 도메인 전문성, 의사소통이 중요하고 분석대상 및 방식에 따른 다양한 분석 주제를 과제 단위 혹은 마스터 플랜 단위로 도출할 수 있어야 한다
분석 기획시 고려사항
| Available Data | Proper Business Use Case | Low Barrier of Execution |
|---|---|---|
| Transaction data | Customer analytics | Cost |
| Human-generated data | Social media analytics | Simplicity |
| Mobile data | Plant and facility management | Performance |
| Machine and sensor data | Pipeline management | Culture |
| Price optimization | ||
| Fraud detection |

출처: https://needjarvis.tistory.com/505
가용 데이터(Available Data)에 대한 고려:
- 데이터 확보가 우선적
- 데이터의 유형에 따라 적용 가능한 솔루션 및 분석 방법이 다름 → 유형에 대한 분석이 선행적으로 이루어져야 함
적절한 활용방안과 유즈케이스(Proper Business Use Case) 탐색 필요:
- 기존에 잘 구현되어 있는 유사 분석 시나리오 및 솔루션을 최대한 활용
장애요소들에 대한 사전계획 수립 필요(Low Barrier of Execution):
- 일회성 분석으로 그치지 않고 조직의 역량으로 내재화 되어야 함 → 충분하고 계속적인 교육 및 활용방안 등의 변화 관리(Change Management)가 고려되어야 함
2절. 분석 방법론
분석 방법론 개요
개요:
- 체계화한 절차와 방법이 정리된 데이터 분석 방법론의 수립이 필수적
- 방법론은 절차(Procedure), 방법(Methods), 도구와 기법(Tools&Techniques), 템플릿과 산출물(Templates&Outputs)로 구성되어 어느 정도의 지식만 있으면 활용이 가능해야 한다
- KDD 분석 방법론
- CRISP-방법론
- 빅데이터 분석 방법론
데이터 기반 의사결정의 필요성:
- 경험과 감에 따른 의사결정 → 데이터 기반의 의사결정
- 기업의 합리적 의사결정을 가로막는 장애요소: 고정 관념(Sterotype), 편향된 생각(Bias), 프레이밍 효과(Framing Effect: 문제의 표현 방식에 따라 동일한 사건이나 상황임에도 불구하고 개인의 판단이나 선택이 달라질 수 있는 현상) 등
방법론의 생성과정:

출처: https://needjarvis.tistory.com/507
| 구분 | 의미 | 예 | 특징 | 상호작용 |
|---|---|---|---|---|
| 암묵지 | 학습과 경험을 통해 개인에게 체화되어 있지만 겉으로 드러나지 않는 지식 | 김치 담그기, 자전거 타기 | 사회적으로 중요하지만 다른 사람에게 공유되기 어려움 | 공통화, 내면화 |
| 형식지 | 문서나 매뉴얼처럼 형상화된 지식 | 교과서, 비디오, DB | 전달과 공유가 용이함 | 표출화, 연결화 |
방법론의 적용 업무의 특성에 따른 모델:
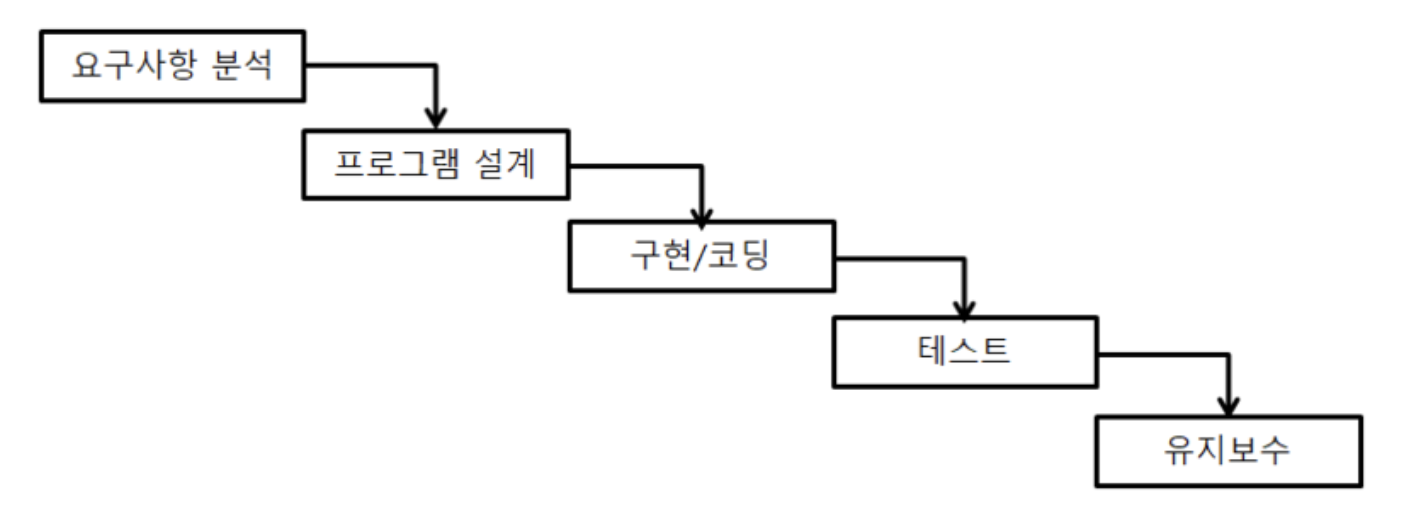
- 폭포수 모델(Waterfall Model)
- 단계를 순차적으로 진행하는 방법으로, 이전 단계가 완료되어야 다음 단계로 진행될 수 있으며 문제가 발견될 시 피드백 과넞ㅇ이 수행된다
- 요구사항 변경이 어려움
- 절차:
- 타당성 검토 -> 계획 -> 요구사항 분석 -> 설계 -> 구현 -> 테스트 -> 유지보수
 출처: https://m.blog.naver.com/roser111/221661276734
출처: https://m.blog.naver.com/roser111/221661276734
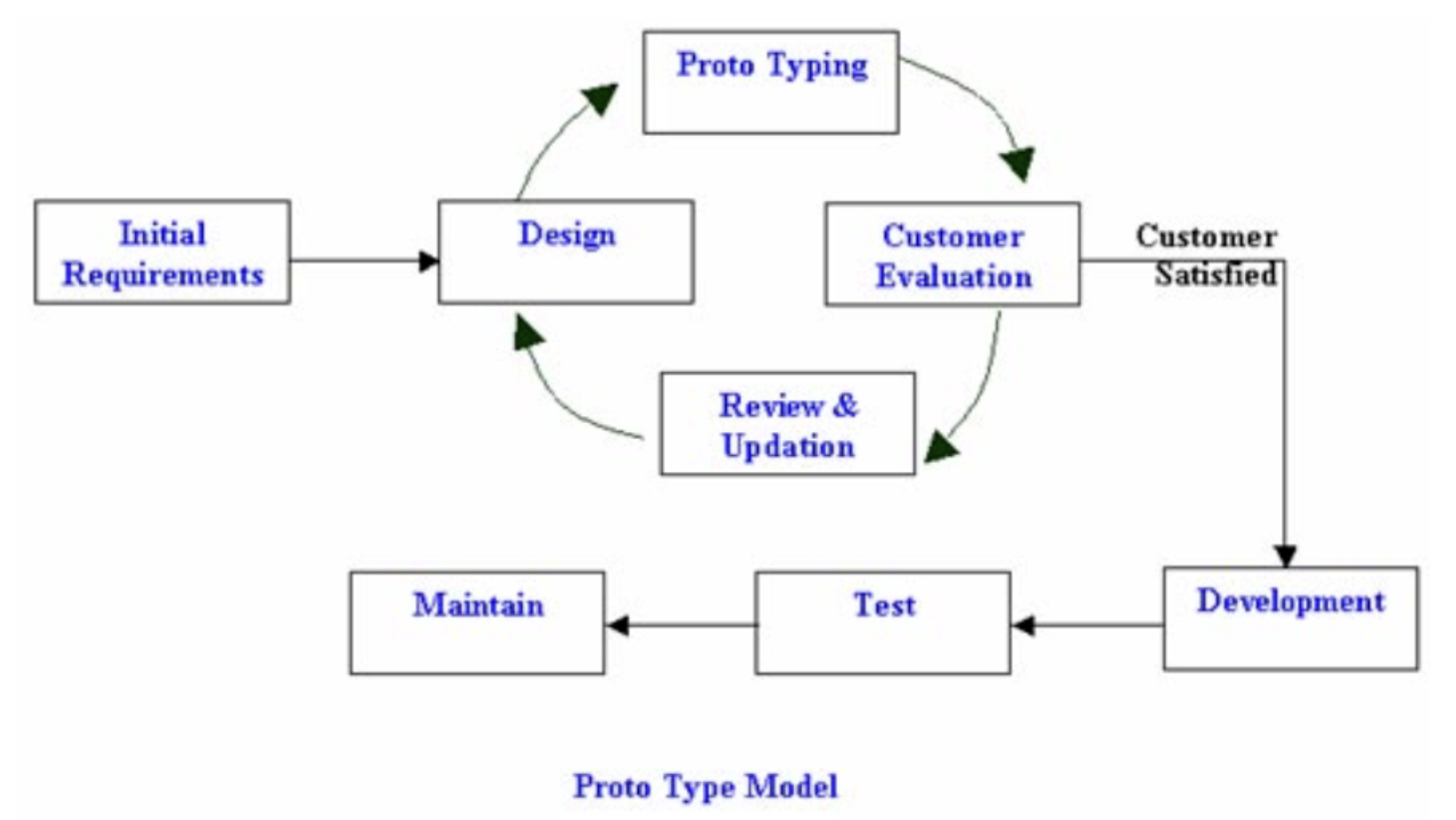
- 프로토타입 모델(Prototype Model)
- 점진적으로 시스템 개발
- 고객의 요구를 완벽히 이해하기 위해 일부분을 우선 개발하여 사용자게에 제공
- 시험 사용 후 사용자의 요구를 분석, 점검, 성능 평가 후 그 결과를 통한 개선 작업을 시행
- ex) 시제품을 만들어서 고객한테 보여주고 피드백을 받아 개선해나가는 방법
- 절차:
- 계획수립 -> 프로토타입 개발 -> 사용자 평가 -> 구현 -> 인수
- 장점: 요구사항이 충실히 반영됨, 결과물을 사용자가 빨리 볼 수 있다, 오류를 초기에 발견
- 단점: 시간과 비용이 많이 듬, 문서작성이 소홀해질 수 있다
 출처: https://bigdown.tistory.com/376
출처: https://bigdown.tistory.com/376
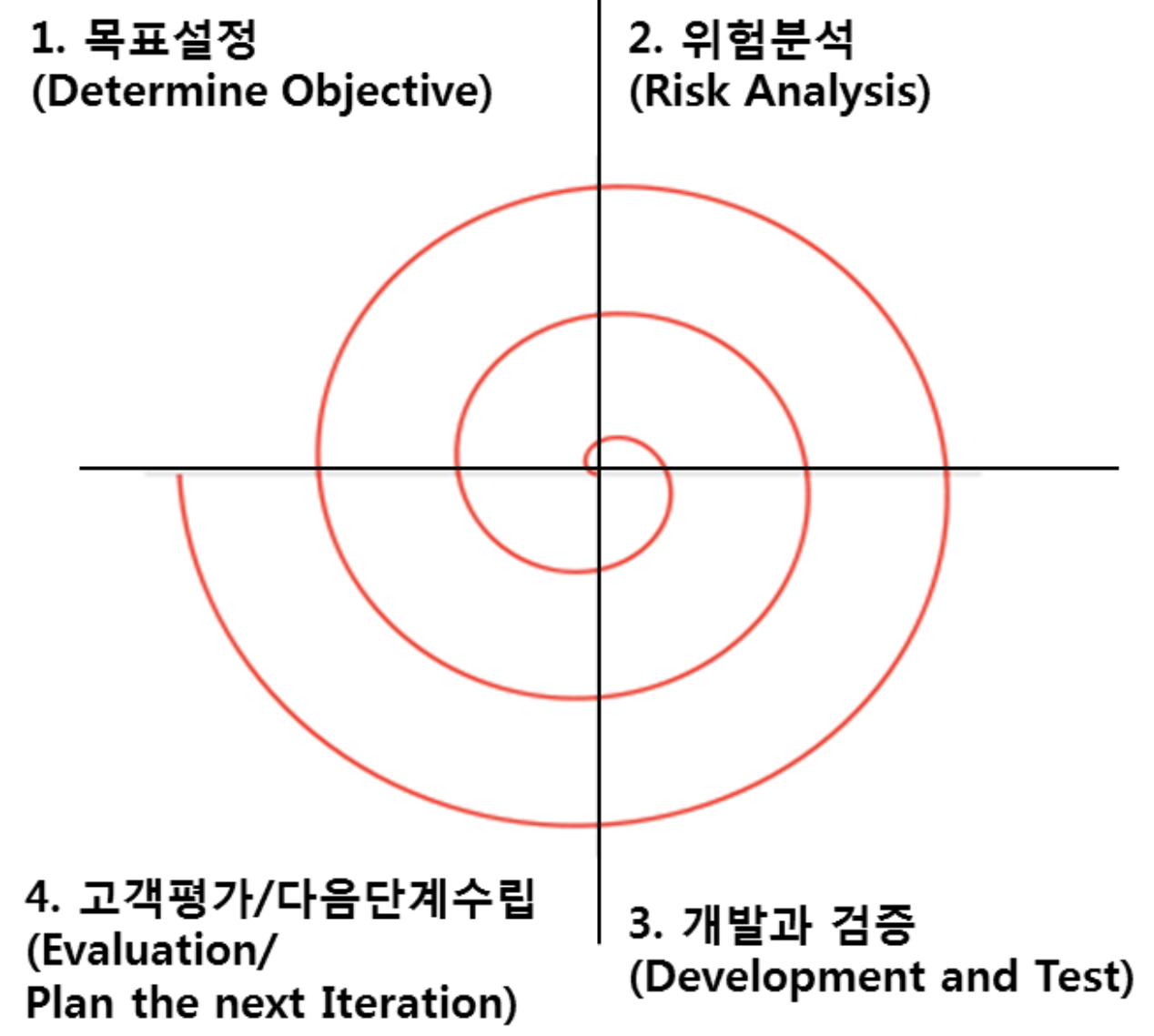
- 나선형 모델(Spiral Model)
- 반복을 통해 점증적으로 개발
- 처음 시도하는 프로젝트에 적용이 용이
- 관리 체계를 효과적으로 갖추지 못한 경우 복잡도 증가 → 프로젝트 진행에 어려움 발생
- 절차:
- 반복: 계획 및 정의 -> 위험 분석 -> 개발 -> 고객 평가
출처: https://m.blog.naver.com/seilius/130185846022
KDD(Knowledge Discovery in Databases) 분석 방법론
개요:
- 1996년 Fayyad가 프로파일링 기술을 기반으로 데이터로부터 통계적 패턴이나 지식을 찾기 위해 활용할 수 있도록 체계적으로 정리한 데이터 마이닝 프로세스
- 데이터마이닝, 기계학습, 인공지능, 패턴인식, 데이터 시각화 등에서 응용
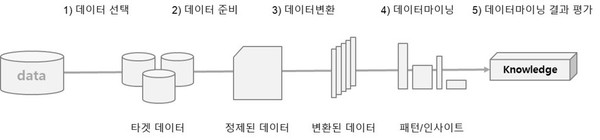
KDD 분석 절차

1. 데이터셋 선택(Selection)
- 분석 대상의 비즈니스 도메인에 대한 이해화 프로젝트 목표 설정이 필수
- 데이터베이스 또는 원시 데이터에서 분석에 필요한 데이터를 선택
- 데이터마이닝에 필요한 목표데이터(Target Data) 를 구성하여 분석에 활용
2. 데이터 전처리(Preprocessing)
- 데이터셋에 있는 잡음(Noise) 과 이상치(Outlier), 결측치(Missing Value) 를 식별하고 필요시 제거하거나 의미있는 데이터로 재처리하여 데이터 셋을 정제
- 추가로 요구되는 데이터 셋이 필요한 경우 데이터 선택 프로세스를 재실행
3. 데이터 변환(Transformation)
- 정제된 데이터에 분석 목적에 맞게 변수를 생성, 선택
- 데이터의 차원을 축소하여 효율적으로 데이터마이닝을 할 수 있도록 데이터에 변경
- 학습용 데이터(Training Data) 와 시험용 데이터(Test Data) 로 데이터 분리
4. 데이터 마이닝(Data Mining)
- 분석목적에 맞는 데이터마이닝 기법을 선택
- 적절한 알고리즘을 적용
- 필요에 따라 데이터 전처리와 데이터 변환 프로세스를 추가로 실행
5. 데이터 마이닝 결과 평가(Interpretation/Evaluation)
- 결과데 대한 해석과 평가
- 분석 목적과의 일치성 확인
- 데이터마이닝을 통해 발견한 지식을 업무에 활용하기 위한 방안 마련
- 필요에 따라 데이터 선택 프로레스에서 데이터마이닝 프로세스를 반복 수행
CRISP-DM(Cross Industry Standard Process for Data Mining) 분석 방법론
개요:
- 1996년 유럽 연합의 ESPRIT에서 있었던 프로젝트에서 시작
- 주요한 5개의 업체들(Daimler-Chrysler, SPSS, NCR, Teradata, OHRA)이 주도
- 계층적 프로세스 모델로써 4개 레벨로 구성
CRISP-DM의 4레벨 구조

- 최상위 레벨은 여러개의 단계(Phases)로 구성, 각 단계는 일반화 테스트(Generic Tasks)
- 일반화 테스크: 데이터마이닝의 단일 프로세스를 완전하게 수행하는 단위
- 일반화 테스크는 구체적인 수행 레벨인 세분화 테스크(Specialized Tasks)로 구성됨
CRISP-DM의 프로세스
- 6단계로 구성
- 각 단계는 단방향으로 구성되어 있지 않고, 단계 간 피즈백을 통해 단계별 완성도를 높이게 되어있다

| 단계 | 내용 | 수행업무 |
|---|---|---|
| 업무이해 Business Understanding | - 비즈니스 관점에서 프로젝트의 목적과 요구사항을 이해 - 도메인 지식을 데이터 분석을 위한 문제 정의로 변경, 초기 프로젝트 꼐획 수립 | - 업무 목적 파악 - 상황 파악 - 데이터 마이닝 목표 설정 - 프로젝트 계획 수립 |
#adsp중요
빅데이터 분석 방법론(3계층 5단계)
- 분석 기획(Planning)
- 데이터 준비(Preparing)
- 데이터 분석(Analyzing)
- 시스템 구현(Developing)
- 평가 및 전개(Deploying)

조직의 분석 성숙도 평가
