
Pandas
Slicing 주의
df.drop([start, end]): end도 포함 
df[start:end]: end 미포함 
명령어:
df.dropna
Parameters: axis : {0 or ‘index’, 1 or ‘columns’}, default 0
결측값을 포함하는 행 또는 열을 제거할지 여부를 결정합니다.
- 0, or ‘index’ : 결측값을 포함하는 행 제거
- 1, or ‘columns’ : 결측값을 포함하는 열 제거
how : {‘any’, ‘all’}, default ‘any’
최소한 하나의 NA 값이 있거나 모든 NA 값이 있는 경우 DataFrame에서 행 또는 열이 제거되는 방식을 결정합니다. - ‘any’ : 만약 NA 값이 하나라도 있으면 해당 행 또는 열 제거
- ‘all’ : 모든 값이 NA인 경우 해당 행 또는 열 제거
thresh : int, optional
non-NA 값의 수를 요구합니다. how와 함께 사용할 수 없습니다.
subset : 열 레이블 또는 레이블 시퀀스, optional
고려할 다른 축의 레이블입니다. 예를 들어, 행을 삭제하는 경우 열의 리스트여야 합니다.
inplace : bool, default False
df.duplicated(subset=[‘column1’, ‘column2’, ‘column3’], keep=False):
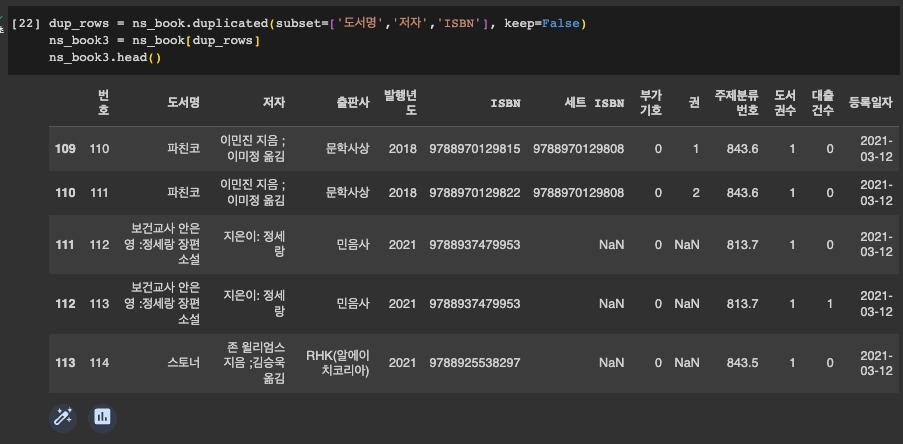
Parameters:
subset : column label or sequence of labels, optional
중복을 식별하기 위해 특정 열만 고려하고자 할 때 사용합니다. 기본적으로 모든 열을 사용합니다.
keep : {‘first’, ‘last’, False}, default ‘first’
중복된 값(있을 경우)을 어떻게 표시할지를 결정합니다.
first: 첫 번째 출현을 제외한 모든 중복 값을True로 표시합니다.last: 마지막 출현을 제외한 모든 중복 값을True로 표시합니다.- False : 모든 중복 값을
True로 표시합니다.
Returns: Series
각 중복된 행에 대한 불리언 시리즈.
df.info()
Parameters:
verbose : bool, optional
- 전체 요약 정보를 출력할지 여부를 결정합니다. 기본적으로 pandas.options.display.max_info_columns의 설정을 따릅니다.
buf : writable buffer, defaults to sys.stdout
- 출력을 전달할 위치입니다. 기본적으로 출력은 sys.stdout에 인쇄됩니다. 출력을 추가 처리해야하는 경우 쓰기 가능한 버퍼를 전달하세요. max_cols : int, optional 요약 정보에서 요약된 출력으로 전환할 때의 기준입니다. DataFrame에
max_cols열보다 많은 열이 있는 경우, 요약된 출력이 사용됩니다. 기본적으로pandas.options.display.max_info_columns의 설정이 사용됩니다.
memory_usage : bool, str, optional
- DataFrame 요소(인덱스 포함)의 총 메모리 사용량을 표시할지 여부를 지정합니다. 기본적으로
pandas.options.display.memory_usage설정을 따릅니다. - True는 항상 메모리 사용량을 표시합니다. False는 메모리 사용량을 표시하지 않습니다. ‘deep’은 “깊은 내부 검사를 포함한 True”와 동일합니다. 메모리 사용량은 인간이 이해할 수 있는 단위로 표시됩니다 (2진 표현). 깊은 내부 검사가 없는 경우에는 각 열의 dtype과 행 수에 따라 값이 동일한 메모리 양을 사용한다고 가정하여 메모리 추정이 이루어집니다. 깊은 메모리 내부 검사에서는 실제 메모리 사용량 계산이 수행되며, 이는 계산 리소스 비용이 발생합니다. 자세한 내용은 자주 묻는 질문(<df-memory-usage>)을 참조하세요.
show_counts : bool, optional
비 null 개수를 표시할지 여부를 결정합니다. 기본적으로 DataFrame이
pandas.options.display.max_info_rows와pandas.options.display.max_info_columns보다 작을 때만 표시됩니다. True는 항상 개수를 표시하고, False는 개수를 표시하지 않습니다.null_counts : bool, optional Returns
np.nan과 None 차이
NA: Not Available의 약자로 누락된 데이터 = 결측값을 의미합니다. 여기에는 NaN, None이 모두 포함된 개념입니다.
NaN: Not a Number의 약자로 숫자 형태의 누락된 데이터 = 결측값을 표현합니다.
None: 파이썬에서 누락된 데이터 = 결측값을 표현합니다.
nf: infinite의 약자로 무한대를 의미합니다. https://brownbears.tistory.com/549에서 설명되어 있습니다.
null: NA와 동일하게 누락된 데이터를 의미합니다. pandas에서는 해당 개념이isnull(),notnull()와 같은 함수 형태로만 나옵니다.
df.apply()
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
func function: 각 열 또는 행에 적용할 함수입니다.
axis: 기본값 0, 함수가 적용되는 축:
- 0 또는 ‘index’: 각 열에 함수를 적용합니다.
- 1 또는 ‘columns’: 각 행에 함수를 적용합니다.
raw: 기본값 False, 행 또는 열이 Series 또는 ndarray 객체로 전달되는지 여부를 결정합니다:
- False: 각 행 또는 열을 Series로 함수에 전달합니다.
- True: 전달된 함수는 ndarray 객체를 받습니다. 만약 NumPy 축소 함수를 적용하는 경우 성능이 훨씬 좋아집니다.
result_type{‘expand’, ‘reduce’, ‘broadcast’, None}, 기본값 None axis=1 (열)일 때만 작동합니다:
- ‘expand’ : 리스트 형태의 결과를 열로 변환합니다.
- ‘reduce’ : 가능한 경우 리스트 형태의 결과를 확장하는 대신 Series를 반환합니다. 이는 ‘expand’의 반대입니다.
- ‘broadcast’ : 결과를 원래 DataFrame의 형태로 방송합니다. 원래 인덱스와 열은 유지됩니다.
tqdm 판다스에 적용하기
위와 같이 선언한 후,
apply()를progress_apply()로 대체합니다.
df.describe(percentiles=[num1, num2, num3])
Parameters:
percentiles : 리스트 형태의 숫자, 선택사항
출력에 포함할 백분위수입니다. 모든 값은 0과 1 사이에 있어야 합니다. 기본값은 [.25, .5, .75]로, 25번째, 50번째, 75번째 백분위수를 반환합니다.
include : ‘all’, 리스트 형태의 dtypes 또는 None (기본값), 선택사항
결과에 포함할 데이터 타입의 화이트리스트입니다. Series에 대해서는 무시됩니다. 옵션은 다음과 같습니다:
‘all’: 입력의 모든 열이 결과에 포함됩니다.
dtypes의 리스트 형태 : 결과를 제공된 데이터 타입으로 제한합니다. 숫자 타입으로 제한하려면
numpy.number를 제출하고, 객체 열로 제한하려면numpy.object데이터 타입을 제출합니다.select_dtypes스타일로 문자열도 사용할 수 있습니다(예:df.describe(include=['O'])). pandas 범주형 열을 선택하려면'category'를 사용합니다.None (기본값) : 결과에는 모든 숫자 열이 포함됩니다. exclude : 리스트 형태의 dtypes 또는 None (기본값), 선택사항, 결과에서 생략할 데이터 타입의 블랙리스트입니다.
Series에 대해서는 무시됩니다. 옵션은 다음과 같습니다:dtypes의 리스트 형태 : 결과에서 제공된 데이터 타입을 제외합니다. 숫자 타입을 제외하려면
numpy.number를 제출하고, 객체 열을 제외하려면 데이터 타입numpy.object을 제출합니다.select_dtypes스타일로 문자열도 사용할 수 있습니다(예:df.describe(exclude=['O'])). pandas 범주형 열을 제외하려면'category'를 사용합니다.None (기본값) : 결과에는 아무 것도 제외되지 않습니다. datetime_is_numeric : bool, 기본값 False 날짜 및 시간 dtypes를 숫자로 취급할지 여부입니다. 이는 열에 대해 계산되는 통계에 영향을 미칩니다. DataFrame 입력의 경우 이는 datetime 열이 기본적으로 포함되는지 여부도 제어합니다.
Returns:
Series 또는 DataFrame
제공된 Series 또는 DataFrame의 요약 통계.
df.quantile()
분위수
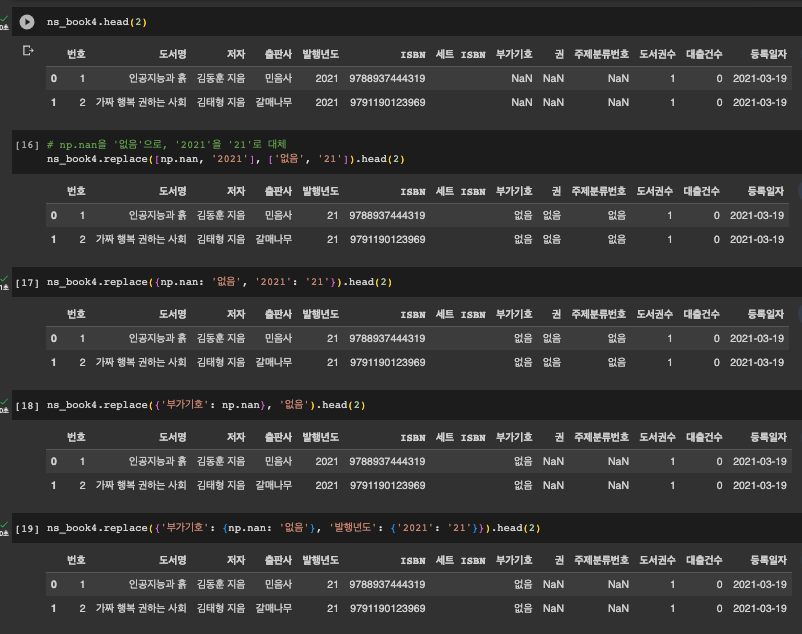
df.replace() 주의점
여러 개를 한꺼번에 실행할 때 형식을 주의해야 합니다
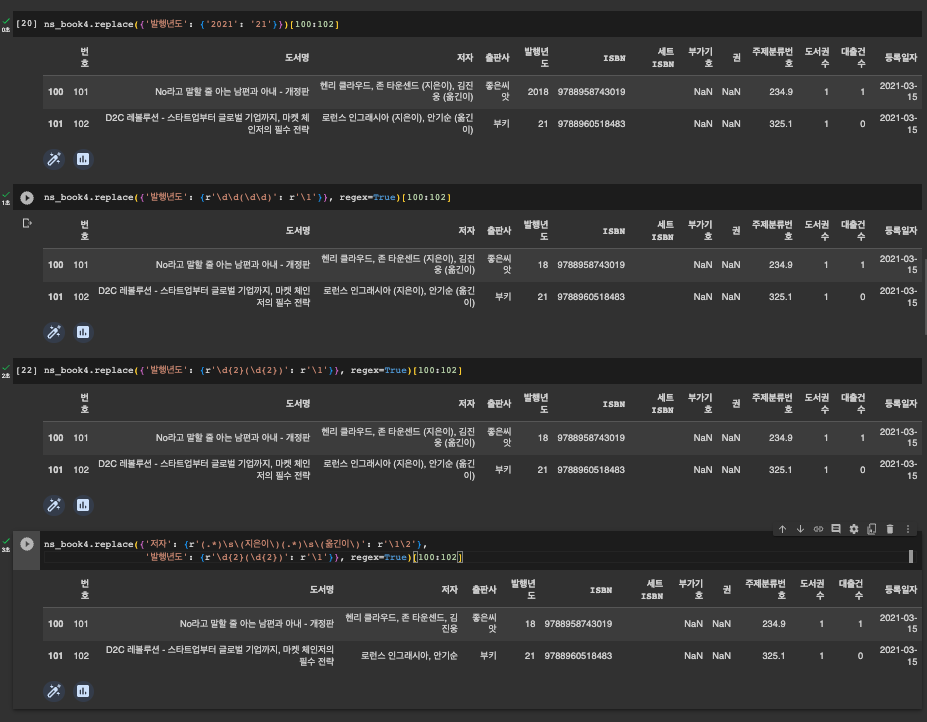
정규표현식
정규화(Normalization/Standarlization) 과정이 필요한 이유
각 속성의 유닛을 맞춰주기 위해