
Chapter 1. 데이터베이스 구축
Section 1. 데이터베이스 개념
1. 데이터베이스 개념
#정처기중요 #공장통운
데이터베이스의 정의 (중요!)
- 통합데이터(Integrated Data)
- 검색의 효율성을 위해 중복이 최소화된 데이터의 모임
- 저장 데이터(Stored Data)
- 컴퓨터가 접근 가능한 저장 매체에 저장된 데이터
- 운영 데이터(Operational Data)
- 조직의 목적을 위해 존재 가치가 확실하고 반드시 필요한 데이터
- 공유 데이터(Shared Data)
- 여러 응용 프로그램들이 공동으로 사용하는 데이터
데이터베이스의 특징
- 실시간 접근성
- 계속적인 변화
- 동시 공유
- 내용에 의한 참조
- 데이터의 독립성
데이터 언어
- DDL(Data Definition Language): 데이터 정의
- DML(Data Manipulation Language): 데이터 조작
- CRUD
- DCL(Data Control Language): 데이터 제어어
- GRANT
- ROLLBACK
- REVOKE
- COMMIT
스키마(Schema)
- 데이터베이스의 구조와 제약조건에 관해 전반적인 명세를 기술한 것
- 개체, 속성, 관계에 대한 정의와 이들이 유지해야 할 제약조건들을 기술한 것
- 스키마는 데이터 사전(Data Dictionary)에 저장
3계층 스키마
- 외부 스키마(External Schema):
- 사용자가 보는 관점
- 논리적 구조 정의
- 여러개 존재
- 개념 스키마(Conceptual Schema):
- 전체적인 제약 조건
- 한개만 존재
- 내부 스키마(Internal Schema):
- 물리적인 제약 조건
#정처기중요 데이터 독립성
- 논리적 독립성
- 응용 프로그램에 영향을 주지 않고 데이터베이스 논리적 구조를 변경할 수 있는 능력
- 개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원
- 물리적 독립성
- 물리 스키마가 변경되어도 내부/개념 스키마에 영향을 미치지 않도록 지원
2. 데이터베이스 관리 시스팀(Database Management System)
- 데이터베이스를 조작하는 별도의 소프트웨어
- 구축하는 틀을 제공
- 데이터를 검색하고 저장
DBMS의 기능
- 데이터 정의
- 데이터 조작
- 데이터 제어
- 데이터 공유
- 데이터 보호
- 데이터 구축
- 유지보수
DBMS의 종류
- 계층형(Hierarchical Database)
- 데이터 간의 관계가 트리 형태의 구조
- 다대다 관계 처리가 불가능하다
- 네트워크형(Network Database)
- 계층 구조에 링크를 추가하여 유연성과 접근성을 높혔다
- 구조가 복잡해 유지보수가 어렵다
- 관계형(Relational Database)
- 키와 값으로 이루어진 데이터들을 행과 열로 구성된 테이블 구조로 단순화
- 객체 지향형(Object-Oriented Database)
- 객체지향 프로그래밍 개념에 기반하여 만듬
- 정보를 객체의 형태로 표현
- 비정형 데이터들을 데이터베이스화할 수 있도록 하기 위해 만들어진 모델
- 객체 관계형(Object-Relational Database)
- 관계형 데이터베이스에 객체 지향 개념을 도입하여 만든 데이터베이스 모델
- 객체지향 개념을 지원하는 표준 SQL사용 가능
- 데이터 타입도 관계형 데이터보이스보다 더 다양하게 추가
- NoSQL
- Not Only SQL: SQL 외에 다양한 특성도 지원
- RDBMS의 복잡도와 용량의 한계를 극복하기 위한 목적
- 비정형 데이터 처리에 유리하지만 스키마 변경이 불가능해 데이터값에 문제가 발생하면 감지가 어렵다
- NewSQL
- RDBMS의 SQL과 NoSQL의 장점을 결합한 관계형 모델
- 확장성과 고가용성을 만족시키려는 목적
Section 2. 데이터베이스 설계
데이터베이스 설꼐 시 고려사항
- 제약조건
- 데이터베이스 무결성
- 일관성
- 회복
- 보안
- 효율성
- 데이터베이스 확장성
데이터베이스 설계 단계
- 요구조건 분석
- 개념적 설계
- ERD
- 논리적 설계
- 특정 데이터모델을 적용한 설계
- 논리적 스키마 생성
- 정규화
- 트랜잭션 인터페이스 설계
- 물리적 설계
- 도메인
- 오브젝트, 접근방법, 트랜잭션분석, 인덱스, 뷰, 데이터베이스 용량설계 등 수행
- 물리적 스키마 생성
- 트랜잭션 세부 설계
- 구현
- 특정 DMBS의 DDL로 기술된 명령문을 컴파일하고, 실행시켜 데이터베이스 스키마 생성
Section 3. 데이터 모델링
데이터모델 구조
- 개체(Entity)
- 개체 타입(Entity type)
- 개체 인스턴스(Entity instance)
- 개체 세트(Entity set)
- 속성(Attribute)
- 관계(Relation)
#정처기중요
데이터모델 표시해야 할 요소
- 구조(Structure)
- 연산(Operation)
- 제약조건(Constraint)
ERD 기호
#정처기중요 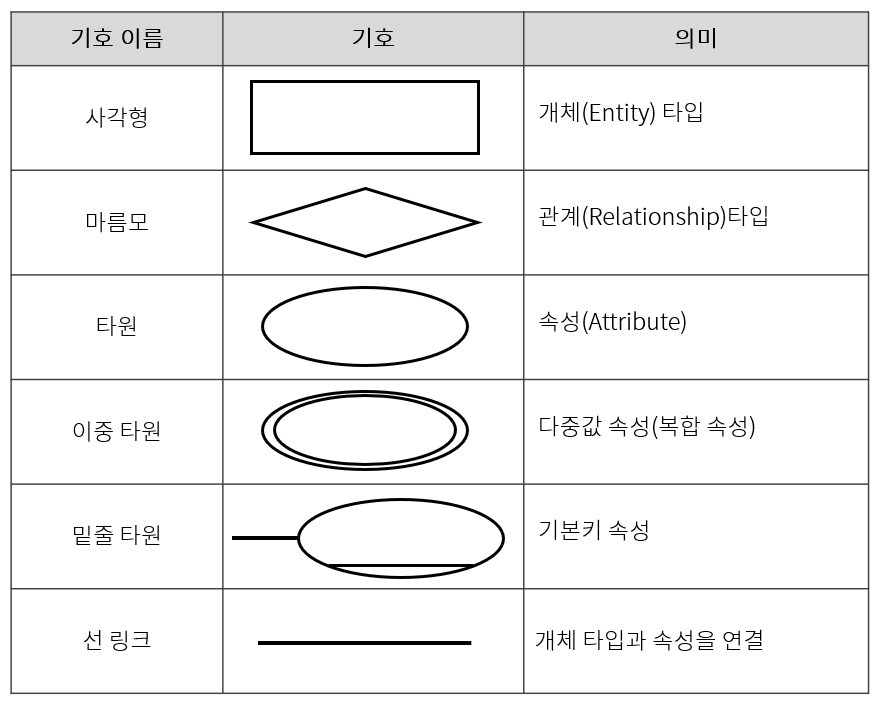 출처: https://www.edrawsoft.com/kr/diagram-tutorial/how-to-create-er-diagrams.html
출처: https://www.edrawsoft.com/kr/diagram-tutorial/how-to-create-er-diagrams.html
데이터 모델의 품질 기준
- 정확성
- 완정성
- 준거성
- 최신성
- 일관성
- 활용성
Section 4. 논리 데이터베이스 설계
논리적 데이터 모델링
- 개념적 설계에서 추출된 실체와 속성들의 관계를 구조적으로 설계하는 단계
- 정규화
정규화(Normalization)
- 중복을 최소화하게 데이터를 구조화
- 중복된 데이터를 허용하지 않음으로서 무결성(Integrity)을 유지할 수 있으며, DB 저장 용량 감소 효과
이상 현성(Anomaly)
- 데이터 중복으로 인해 릴레이션 조작 시 예상하지 못한 곤란한 현상이 발생
- 이상은 속성들 간에 존재하는 여러 종류의 종속 관계를 하나의 릴레이션에 표현할 때 발생
#정처기중요 이상의 종류
- 삽입 이상: 삽입 시 불필요한 데이터가 함께 삽입되는 현상
- 삭제 이상: 한 튜플을 삭제할 때 연쇄 삭제 현상으로 인해 정보 손실
- 갱신 이상: 튜플의 속성값을 갱신할 때 일부 튜플의 정보만 갱신되서 정보에 모순이 생기는 현상
#정처기중요 
Section 5. 물리 데이터베이스 설계
#정처기중요
반정규화
- 시스템의 성능향상과 개발 편의성 등을 위해 정규화에 위배되는 중복을 허용
- 정규화된 엔티티, 속성, 관계를 시스템의 성능 향상과 개발 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링 기법
고려사항
- 무결성이 깨질 수 있다
- 읽기 속도는 향상되지만, 삽입/삭제/수정 속도는 느려짐
- 저장 공간의 효율이 떨어짐
- 유지보수가 어려워짐
적용 순서
- 반정규화 대상 조사
- 다른 방법으로 유도
- 반정규화 수행
데이터베이스 이중화
- 장애발생 시 데이터베이스를 보호하기 위한 방법으로 동일한 데이터베이스를 중복시켜 동시에 갱신하여 관리하는 방법
- 시스템의 지속적인 정상 운영이 가능한 고가용성(High Availability) 서버로 구성하는 것
데이터베이스 이중화의 분류
- Eager 기법: 트랜잭션 수행 중에 발생한 변경은 발생 즉시 모든 이중화서버로 전달하여 변경 내용 반영
- Lazy 기법: 트랜잭션의 수행이 완전히 완료된 후에 변경 사실에 대한 새로운 트랜잭션을 작성함
데이터베이스 이중화의 종류
- Active-Active
- Active-Standby
데이터베이스 백업
- 전체 백업
- 증분 백업
- 차등 백업
- 실시간 백업
- 트랜잭션 로그 백업
- 합성 백업
복구 시간 목표/복구 시점 목표
- 복구 시간 목표(RTO)
- 복구 시점 목표(RPO)
데이터베이스 암호화
- API 방식
- Plug-in 방식
- TDE 방식
Section 6. 데이터베이스 물리 속성 설계
파티셔닝
- 데이터베이스를 여러 부분으로 분할하는 것
- 데이터가 너무 커져서 조회하는 시간이 길어질 때 또는 관리 용이성, 성능, 가용성 등의 향상을 이유로 분할
파티셔닝의 종류
- 수평분할
- 수직 분할
분할 기준
- 범위 분할
PARITITON BY RANGE
- 목록 분할
PARITITON BY LIST
- 해쉬 분할
- 라운드 로빈 분할(Roud Robin Partitioning)
- 합성 분할
클러스터 설계
- 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법
특징:
- 디스크 I/O를 줄여준다
- 테이블 사이에 조인이 발생할 경우 처리 시간이 단축
- 데이터 조회 성능을 향상시키지만 데이터 저장, 수정, 삭제나 Full Scan시 성능 저하
- 데이터의 분포도가 넓을수록 유리함
- 파티셔닝된 테이블에는 클러스터링 불가
인덱스(Index)
- 추가적인 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조
- 데이터를 빠르게 추출
인덱스의 종류
- 클러스터 인덱스
- 데이블당 1개만 허용되며, 해당 컬럼을 기준으로 테이블이 물리적으로 정렬
- 넌클러스터 인덱스
- 약 240개 생성 가능
- 인덱스 페이지만 정렬
- 리프 페이지가 데이터가 아니라 데이터가 위치하는 포인터
- 클러스터보다 검색 속도는 느리지만 데이터의 입력, 수정, 삭제는 더 빠름
- 용량을 더 차지함
- hint를 준다
- 밀집 인덱스
- 레코드 각각에 대해 하나의 인덱스가 만등러짐
- 희소 인덱스
- 레코드 그룹 또는 데이터 블록에 대해 하나의 인덱스가 만들어짐
뷰(View)
- 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블
- 뷰는 실제로 데이터를 저장하고 있지 않으며, 논리적으로만 존재
- 데이터베이스 사용자는 실제로 데이터가 존재하는 테이블과 동일하게 뷰를 조작할 수 있다
1
2
3
CREATE OR REPLACE VIEW [view_name] AS SELECT [field_name1], [field_name2]
FROM [table_name]
WHERE [조건];
1
DROP VIEW [view_name]
시스템 카탈로그
- 데이터베이스에 저장되어 있는 모든 데이터 개체들에 대한 정의나 명세에 대한 정보가 수록되어 있는 시스템 테이블
- 데이터 사전(Data DIctionary)라고도 한다
- 시스템 카탈로그에 저장된 내용을 메타 데이터라고 한다
Section 7. 관계 데이터베이스 모델
관계 데이터 모델
- 데이터의 논리적 구조가 릴레이션, 즉 테이블 형태의 평면 타일로 표현되는 데이터 모델
관계 데이터 릴레이션의 구조
- 커디널리티: 튜플의 개수
- 차수: 속성의 개수
릴레이션
- 데이터들을 2차원 테이블의 구조로 저장한 것
- 릴레이션의 구성
- 릴레이션 스키마: 속성의 구조
- 릴레이션 인스턴스: 실제로 저장된 데이터의 집합
- 릴레이션의 특징
- 튜플의 유일성
- 튜플의 무순서성
- 속성의 무순서성
- 속성의 원자성
- 튜플들의 삽입, 갱신, 삭제작업이 실시간으로 일어나므로 릴레이션은 수시로 변한다
관계데이터 언어(관계대수, 관계해석)
- 원하는 데이터를 얻기 위해 데이터를 어떻게 찾는지에 대한 처리 과정을 명시하는 절차적인 언어
- 연산의 순서를 명시
순수 관계 연산자
- SELECT: ∂
- PROJECT: π
- JOIN: ∞
- DIVISION: ÷
- 릴레이션 S의 모든 튜플과 관련이 있는 릴레이션 R의 튜플들을 반환
(R)÷(S1)
- AND (^)
일반 집합 연산자
- 합집합(UNION): U
- 교집합(INTERSECTION):
- 차집합(DIFFERENCE): -
- 교차곱(Cartesian Product): X
관계 해석
- 관계 해석은 원하는 정보가 무엇이라는 것만 정의하는 비절차적 특성
- 튜플 관계해석, 도메인 관계해석
#정처기중요 연산자 
Section8. 키와 무결성 제약조건
#정처기중요 
트랜잭션
- 데이터베이스의 상태를 변환시키는 하나의 논리적인 기능을 수행하는 작업 단위
#정처기중요
트랜잭션의 성질(ACID)
- 원자성(Atomicity): 모두 반영되거나 모두 반영되지 말아야한다
- 일관성(Consistancy)
- 독립성(Isolation)
- 영속성(Durability)